医学人文讲堂

【北大医学人文讲堂第85期】杜建:医学知识计量学方法及其在管理与决策中的应用
时间:2021-04-19 02:00:00 来源:
2021年4月12日上午,北京大学健康医疗大数据国家研究院杜建老师应邀来我院进行“医学知识计量学方法及其在管理与决策中的应用”专题讲座,讲座由张大庆教授主持,三十余位师生参加。

讲座主要围绕相关概念及其演进、科学发现“从产生到认可”的定量模拟、医学知识计量学研究框架及其应用三个方面展开。
一、 相关概念及其演进
杜老师首先回顾了文献计量学、信息计量学到知识计量学的概念及其演进,从宏观、中观和微观三个层面分析了不同计量学(metrics discipline)的研究对象与研究内容。
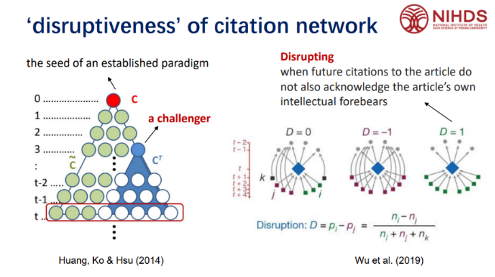
随后,杜老师分享了几个很有意思的指标——破裂指数和颠覆因子(disruptiveness),认为两者存在相似之处。对于破裂指数,假设论文“c”引领了这个领域,后边的相关文章都在引用它、追随它。但是突然出现了一个挑战者,后边这些文章就不再引用“c”而是引用挑战者了,就相当于挑战者把这个知识网络构成破裂了。所以可以计算每一个点的“破裂指数”,分析它给整个网络是不是带来了变化?谁的破裂指数高,相当于它的颠覆性是比较强的。
对于颠覆因子,杜老师针对“D=1”、“D=-1”和“D=0”三种情形进行了说明。当“D=1”时,如果某位学者发表了一篇文章,后边的文章都在引用这篇文章而不引用父辈文献,那么其颠覆因子就很强。
紧接着,杜老师对网络科学中的结构洞理论进行了详细介绍。认为结构洞起到了中介和桥接的作用。如果在科学发展过程中,一篇文献也起到这样的作用,那么它就很重要。
最后杜老师分享了一个重要的工具——知识图谱。指出有两种理解方式,一是文献计量学范式下的科学知识图谱;二是计算机科学范式下的Knowledge Graph。前者从本质上侧重二元共现关系;后者强调三元组因果关系。认为计算机领域的Knowledge Graph概念更适合于医学领域,或者叫医疗知识图谱。
二、 科学发现“从产生到认可”的定量模拟
如何去模拟科学发现“从产生到认可”这个过程,杜老师列举了两个故事进行详细说明。
故事1.成功上市新药背后的科学结构和创新规律
在生物医药领域,转化医学或者做科研最终的目标可能是追求基础研究能够治疗疾病,产生出新药、能够上市等。因此,杜老师提出了三个问题:成功上市新药背后的科学是什么样的?技术是什么样的?这些创新有什么样的规律?并依据上市新药和科学出版物数据建立了一个模型,用于分析生物医药模式下成功上市新药背后的科学结构和创新规律。对于各个学科在新药成功上市的作用,杜老师指出,除了药理学本身,临床医学对于最后的新药成功上市的作用非常重要,所占份额最大。而对于科学与技术的协同作用,认为二者大致是1:2的关系,如果要做成一个好的新药创新,其实大部分建立在已有的技术基础之上,但是会参考一部分的科学进展。
故事2:从0到1的原创研究被学术共同体的认可规律
杜老师首先举例科技部等5个部门关于加强从0~1的基础研究的文件,强调国家对从0到1的原创的重视。并分享了自身关于“睡美人文献”的研究经历,阐释“睡美人文献”的含义,认为“睡美人文献”是科学计量学的概念,指的是一篇文章发表出来之后,很长一段时间内被引次数很少,或者基本上没有人理。若干年之后,突然受到人们的关注而高被引。
随后他对其背后的原因进行了剖析,认为“睡美人文献”的出现是因为其超前性和变革性,从而受到无意忽视或有意抵制。“睡美人文献”的被引突增到底是谁诱发的?对此有另一个概念“王子文献”,王子唤醒了睡美人,即“王子文献”引发了它的被引突增,把它引入到学术界,把它介绍给学术界,如同千里马与伯乐一般。并提出关于识别“王子文献”的4个定量标准。对于文献的负面引用与反驳,杜老师强调,负面引用并不一定就是不好的。传统的观点说一定要看正面引用,但是负面引用和科学争论其实对于科学的发展是非常重要的。负面引用常表现为数据结果之争,但概念观点之争的负面引用更重要,更可能孕育着科学突破。
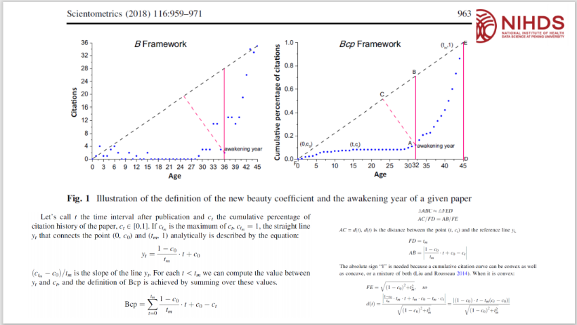
紧接着,杜老师提出了一个指标Bcp指数用于自动检测“睡美人文献”,并分享其对该指数的完善与具体应用。其机理是引文动力学,体现了专家学者们对现有文献的选择和认可过程。并强调原创做出来之后,它一般是缓慢的逐渐被人们认可的过程。这恰恰是原创的科学工作的内在特征。
最后杜老师总结了原始创新的三个基本特征:从性质看,属于“从0到1”的首创,是“无中生有”的质变;从过程看,属于不连续事件和小概率事件,具有很强的探索性和不确定性;从结果看,具有突破性、超前性和被承认的滞后性。
三、 医学知识计量学研究框架及其应用
杜老师指出现代科学的特点是科学出版物及其相关数据集呈指数增长,知识主张(knowledge claims)以非结构化文本为主要形式进行表达,传统的人脑阅读模式根本无法有效处理。在现代科学背景下,我们面临着严峻的挑战:如何跟上日益增长的科学知识的进展,进而开展二阶研究以发现新知识,开展证据分析以循证决策,开展科学预测以优化资源配置,对知识的可计算化提出了迫切需求。
随后,杜老师提出了两种知识可计算化的建模方法:基于知识的建模和基于文档的建模。
基于知识的建模更侧重于知识的内在逻辑,将人读的知识格式转换为机器可读、可执行的知识格式。如动脉粥样硬化性心血管疾病(ASCVD)预测的中国模型、临床用药物基因组学实施指南等,供临床使用。
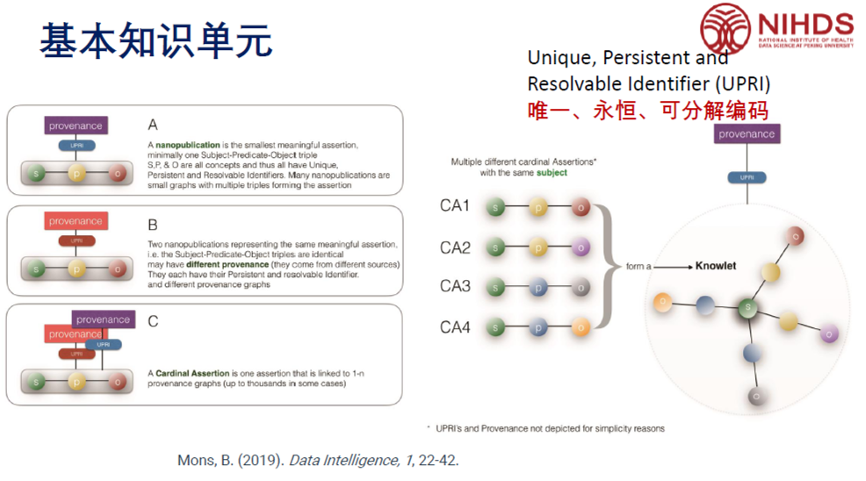
基于文档的建模更侧重于知识的表现形式,将医学证据和知识主张结构化,将“不确定性”引入知识计算。杜老师分享了一个有趣、具有颠覆性的观点,即荷兰莱顿大学医学中心教授Barend Mons,他提出了一个观点即我们现在都在做数据挖掘,那为什么要把数据埋藏起来?为什么在一开始发布这个数据、发表这个文章的时候,就不能以结构化、可计算这种形式发表?杜老师认为不仅应关注结构化的知识单元(knowledge unit),还要关注知识背景 (knowledge context),即元知识。他还介绍了nanopublication等新型的可计算医学知识的表示模型及其最新进展。
最后,杜老师总结道,进入“可解释的、可计算的、可管理的”的计算时代,知识也将被视为可计算的对象。在科学出版物和现有知识库一阶科学知识的基础上开展二阶科学研究,生成新的一阶知识。计算科学家以从文献和数据库中提取的知识为基础,对其进行计算处理,挖掘出可以在实验中得到检验的新假设。实验科学家和计算科学家之间的合作已成为科学发现的新趋势。
杜老师结合自己多年的研究经验和丰富的案例分享,让我们进一步认识到医学领域文献计量学、信息计量学和知识计量方法在管理与决策中的应用和作用。促进了我院师生对计量学方法的了解与使用。
(供稿:医学史与医学哲学系 莫小聪)